


Have you ever considered how much your business could lose from just an hour of downtime? For most companies, even a brief disruption can result in lost revenue, damaged customer trust, and operational inefficiencies. In today’s fast-paced digital world, ensuring continuous uptime isn’t just a technical goal—it’s a cornerstone of business success. Uptime is more than a metric; it’s a measure of reliability and your ability to deliver consistent value to your customers.
Downtime doesn’t just happen by chance. It’s often the result of overlooked system maintenance, cybersecurity breaches, or inadequate disaster recovery planning. Yet, with the right strategies and tools, businesses can minimize these risks and ensure their systems operate seamlessly. This blog explores essential strategies to maximize uptime, helping you achieve business continuity and growth, no matter the challenges.
To stay ahead, many businesses are turning to advanced tools like Deskera ERP. Deskera ERP goes beyond traditional resource planning, offering real-time monitoring, predictive analytics, and robust reporting features that help businesses mitigate risks and reduce downtime. With its mobile accessibility and AI assistant, David, Deskera ERP empowers you to make proactive decisions and streamline your operations. By leveraging such tools, businesses can focus on growth without worrying about system disruptions.
Maximizing uptime isn’t just about technology—it’s about strategic foresight and consistent execution. Whether you’re managing IT infrastructure, logistics, or customer-facing platforms, the strategies outlined in this guide will help you optimize uptime, enhance productivity, and drive sustainable growth for your business.
What Is Uptime?
Uptime refers to the amount of time a system, network, or service is operational and available for use without interruptions. It is typically expressed as a percentage of total time within a specific period, such as a day, month, or year. For example, an uptime of 99.9% means the system was functioning without downtime for 99.9% of the time during the defined period.
Uptime is a critical metric in industries reliant on technology, such as IT, manufacturing, and e-commerce, as it directly impacts productivity, customer satisfaction, and revenue. High uptime ensures seamless operations, while frequent downtime can lead to lost opportunities and a damaged reputation.
In essence, uptime measures reliability, and businesses aim for maximum uptime to maintain efficiency and trust.
Uptime vs. Availability: Understanding the Key Differences
While both uptime and availability are essential metrics used to measure system performance, they are not exactly the same and are often confused with one another.
Uptime refers to the actual amount of time a system or service is functioning without interruption. It is a specific measurement of time, usually expressed as a percentage, such as 99.9% uptime, which indicates the system was working properly for that percentage of time within a given period. Uptime focuses on the operational status of the system during that period.
Availability, on the other hand, is a broader concept that refers to the ability of a system or service to be accessible and functional when needed. It includes not just uptime but also factors like how quickly the system can recover from downtime, and the ability to handle unexpected loads or failures. Availability takes into account not only whether the system is up but also how quickly and reliably it can be restored after an outage.
In summary, uptime measures the actual time a system is operational, while availability includes uptime and the system's ability to recover quickly and continue operating in the face of challenges.
Why Uptime is a Key Metric for IT Leaders and Business Owners
Uptime is a crucial metric for both IT leaders and business owners, as it directly influences productivity, customer satisfaction, and overall business performance. Ensuring high uptime is essential for smooth operations and sustaining growth in any organization.
Here's why uptime matters to both groups:
For IT Leaders:
- Minimizes System Failures: High uptime ensures that systems are operating continuously without interruptions, reducing technical disruptions.
- Increases Operational Efficiency: Consistent uptime leads to fewer technical issues, improving the efficiency of the entire workforce.
- Better Resource Management: Reliable uptime allows IT teams to allocate resources more effectively and address issues proactively.
For Business Owners:
- Builds Customer Trust: High uptime signals reliability, which helps retain customer trust and satisfaction.
- Protects Revenue: Even brief periods of downtime can result in lost sales, missed opportunities, and reputational damage.
- Ensures Business Continuity: Uptime is vital for keeping critical systems, such as e-commerce platforms and financial tools, always available to support business operations.
For Both:
- Supports Growth and Scalability: With high uptime, businesses can scale their operations without worrying about system availability or reliability.
- Helps in Decision-Making: Tracking uptime metrics allows both IT leaders and business owners to identify patterns and make informed decisions on improvements.
In summary, uptime is a cornerstone of operational success, impacting not only technical aspects but also customer satisfaction and business growth. Prioritizing uptime ensures that organizations maintain stability, efficiency, and a competitive advantage.
How to Calculate Uptime
Calculating uptime is an essential step in measuring the reliability and availability of a system or service. The formula for uptime is straightforward and is typically expressed as a percentage. Here's a step-by-step guide:
1. Uptime Formula
The basic formula to calculate uptime is:
Uptime (%) = [(Total Time - Downtime) / Total Time] × 100
- Total Time: The total amount of time the system was expected to operate within a given period (e.g., one year, one month, etc.).
- Downtime: The total amount of time the system was unavailable during the same period.
2. Example Calculation
Imagine a service is expected to operate continuously over 30 days. Here's how you can calculate its uptime:
- Total Time: 30 days = 30 × 24 hours = 720 hours
- Downtime: 2 hours
Uptime (%): [(720 - 2) / 720] × 100 = (718 / 720) × 100 ≈ 99.72%
3. Measuring Downtime
To accurately measure downtime:
- Use monitoring tools that log incidents of unavailability.
- Record the exact start and end times of each downtime event.
- Aggregate the total downtime over the reporting period.
4. Considerations When Calculating Uptime
- Time Period: Define a clear period for measurement (daily, monthly, annually).
- Maintenance: Decide if planned maintenance will be included as downtime.
- System Scope: Specify which parts of the system or network are being evaluated.
By tracking uptime regularly and striving for improvement, businesses can ensure higher reliability and better customer satisfaction.
Industry Standards for Uptime and What They Mean in Practice
Uptime standards are crucial benchmarks that define how reliable a system, service, or platform needs to be to ensure minimal disruptions and maintain business operations.
These standards are typically expressed as percentages, and each level has a significant impact on both operational performance and customer experience.
Understanding these benchmarks helps businesses set realistic expectations, measure performance, and implement improvements to minimize downtime.
Common Uptime Percentages and Their Implications
- 99.9% Uptime (8 Hours of Downtime Per Year): A 99.9% uptime is often considered the minimum acceptable level for many industries, especially those dealing with e-commerce, SaaS, and IT services. This standard allows for approximately 8 hours of downtime per year, which may seem manageable but can still be disruptive for mission-critical services. For example, an online store or payment processor may experience losses in revenue and customer trust during these 8 hours, emphasizing the need for robust backup systems and disaster recovery plans.
- 99.99% Uptime (52 Minutes of Downtime Per Year): A 99.99% uptime is commonly sought by industries where reliability is paramount, such as healthcare, finance, and cloud-based services. With only 52 minutes of downtime per year, this standard reduces the impact of system failures and service interruptions. For businesses, this level of uptime typically involves significant investments in infrastructure, redundancy, and monitoring systems to ensure minimal disruptions and rapid recovery in case of failures.
- 90% to 95% Uptime (438 to 876 Hours of Downtime Per Year): Uptime between 90% and 95% is generally unacceptable for most businesses, especially in industries that require continuous service availability. With 438 to 876 hours of downtime per year (18 to 36 days), such a level of uptime results in frequent disruptions, operational inefficiencies, and frustrated customers. Any business that falls into this category likely needs to overhaul its infrastructure, processes, and support systems to improve reliability and avoid severe losses.
- 95% to 99% Uptime (88 to 438 Hours of Downtime Per Year): Uptime in the 95% to 99% range can still cause considerable operational setbacks. With 88 to 438 hours of downtime annually, businesses may struggle to maintain customer satisfaction, especially in industries where downtime impacts service delivery. This level of uptime is often seen in smaller organizations or legacy systems with limited resources, but it should be viewed as a target for improvement, as downtime can severely harm brand reputation and financial performance.
- Less Than 90% Uptime (876 or More Hours of Downtime Per Year): Uptime of less than 90% is a major red flag for any business. With more than 876 hours (36 days) of downtime per year, systems are essentially unreliable, resulting in lost revenue, operational chaos, and a significant loss of customer trust. Businesses operating with such low uptime should immediately focus on upgrading their infrastructure, implementing modern tools, and revising their IT strategies to bring their systems up to acceptable standards.
What These Percentages Mean in Practice
The higher the uptime percentage, the more reliable and resilient the system is. For businesses, this means less time dealing with system failures, more time for productive work, and a more satisfied customer base.
However, achieving higher uptime percentages often requires substantial investments in hardware, software, personnel, and maintenance processes. Systems with higher redundancy, frequent updates, advanced monitoring tools, and disaster recovery plans are essential to achieving and maintaining these high uptime percentages.
In practice, businesses should aim for the highest uptime possible based on their specific needs, resources, and industry demands. By understanding the relationship between uptime percentages and downtime hours, organizations can set realistic service level agreements (SLAs), develop proactive maintenance strategies, and mitigate risks that could threaten their operations and customer satisfaction.
Common Causes of Downtime
Downtime can occur for various reasons, ranging from technical glitches to human error. Identifying the root causes of downtime is essential for businesses to implement proactive strategies that minimize disruptions and ensure continuous operations.
Below are some of the most common causes of downtime:
1. Hardware Failures
- Server Crashes: Servers are the backbone of most IT infrastructures, and when they fail, it can bring systems to a halt. Hardware failures, including malfunctioning hard drives, memory, or power supply units, often lead to unplanned downtime.
- Network Equipment Failures: Routers, switches, and other networking hardware can experience issues that disrupt connectivity, resulting in outages for online platforms and internal systems.
2. Software Bugs and System Errors
- Unpatched Software: Using outdated or unpatched software can lead to compatibility issues or bugs that crash systems. Frequent updates and patches are necessary to maintain system stability.
- Software Conflicts: Conflicts between applications or system updates can cause crashes or performance degradation, leading to downtime until the issue is identified and resolved.
3. Human Error
- Mistakes During Maintenance or Updates: IT personnel performing system maintenance or updates may make errors that inadvertently cause downtime. Incorrect configurations, missed steps, or overlooked dependencies can bring systems offline.
- Poorly Managed Changes: Deploying new software or hardware without thorough testing or proper change management processes can lead to compatibility issues or system failures.
4. Cybersecurity Attacks
- Hacking and Data Breaches: Cybercriminals can exploit vulnerabilities in your systems, leading to data breaches, ransomware attacks, or denial-of-service attacks that disrupt service availability and cause downtime.
- Malware Infections: Malware infections can compromise system functionality, slow down performance, or disable services altogether, resulting in downtime while the issue is addressed.
5. Power Outages
- Electrical Failures: Unexpected power cuts or fluctuations can shut down servers, data centers, or other critical infrastructure, causing significant downtime until power is restored or backup systems kick in.
- Inadequate Backup Power: Businesses without sufficient backup power solutions, such as UPS (Uninterruptible Power Supply) systems or generators, may experience extended downtime during power failures.
6. Natural Disasters
- Floods, Fires, Earthquakes: Natural disasters can damage physical infrastructure, including servers, data centers, and network cables, leading to extended downtime until repairs are made.
- Weather-Related Interruptions: Severe weather events, such as storms or snowstorms, can impact business operations, especially when supply chains, transportation, and communication systems are affected.
7. Network Failures
- ISP Outages: Internet Service Provider (ISP) disruptions or network failures can render your systems inaccessible to employees or customers, causing downtime until connectivity is restored.
- Traffic Overload or Bottlenecks: High traffic volumes or network congestion can overload systems, leading to slowdowns or service unavailability.
8. Resource Limitations
- Insufficient Storage or Capacity: When storage or system resources are exhausted (e.g., disk space or CPU), it can result in performance issues or system crashes, leading to downtime.
- Under-Scaled Infrastructure: A lack of scalability in infrastructure, particularly in the cloud or server environments, can result in downtime when the system is unable to handle increased demand.
9. Supply Chain and Vendor Issues
- Third-Party Service Failures: Downtime can also be caused by issues with third-party vendors or service providers, such as cloud hosting companies, payment processors, or software providers.
- Delayed Deliveries: Delays in receiving essential hardware, software, or replacement parts can halt system restoration efforts and extend downtime.
In summary, downtime can be caused by a wide range of factors, both internal and external to the organization. Understanding these common causes allows businesses to develop preventive measures and contingency plans that minimize the risk and duration of downtime, ensuring systems remain operational and reliable.
The Far-Reaching Impact of Downtime
Downtime doesn't just cause a temporary disruption; its impact can ripple throughout an organization, affecting various aspects of operations, customer relations, and financial health.
Here’s how downtime can have far-reaching consequences:
1. Lost Productivity
- Employee Disruption: When systems go down, employees can’t access critical tools or data, resulting in wasted time and stalled work.
- Operational Delays: Projects and tasks that depend on technology get delayed, which affects deadlines and workflow across departments.
- Increased Costs: To recover from downtime, companies often need to allocate additional resources to get systems back online, leading to unplanned expenses.
2. Erosion of Customer Trust
- Service Interruptions: Customers expect reliable service, especially in today’s 24/7 digital world. Downtime can lead to missed orders, failed transactions, or delayed responses, harming customer trust.
- Brand Reputation: Frequent downtime or prolonged outages tarnish a company’s reputation, potentially leading to negative reviews and loss of customer loyalty.
- Loss of Business: Customers may turn to competitors if they can’t rely on your services to be available when needed, leading to long-term revenue loss.
3. Financial Impact
- Lost Revenue: E-commerce sites, payment systems, and sales platforms directly lose revenue during downtime, particularly if transactions are interrupted.
- Legal and Compliance Risks: For industries requiring strict uptime (e.g., healthcare, finance), downtime can lead to violations of regulations, causing fines or legal repercussions.
- Operational Overheads: Extended downtimes lead to increased support costs, such as hiring external experts or using emergency services to address the issue quickly.
4. Damage to Competitive Advantage
- Missed Opportunities: Downtime prevents businesses from capitalizing on market opportunities or responding to customer needs in real time, allowing competitors to fill the gap.
- Innovation Stagnation: If teams spend time addressing downtime instead of innovating, business growth and competitive advantages slow down.
In short, downtime creates a ripple effect that touches almost every aspect of a business, from day-to-day productivity to long-term financial performance and customer relationships. By prioritizing uptime, businesses protect not only their operations but their reputation and bottom line.
Key Strategies to Maximize Uptime
Maximizing uptime is crucial for businesses that rely on continuous access to services and systems. The longer the uptime, the more productive and reliable an organization becomes.
Implementing effective strategies to ensure system stability and minimize downtime is essential for maintaining customer trust, revenue, and operational efficiency.
Below are key strategies that businesses can adopt to maximize uptime:

1. Implement Redundancy and Failover Systems
- Server Redundancy: Using multiple servers, both onsite and in the cloud, ensures that if one server goes down, another can take over, preventing system downtime.
- Network Redundancy: Implementing multiple network paths (e.g., dual internet connections or backup data centers) ensures connectivity even if one path fails.
- Power Redundancy: Utilize uninterruptible power supplies (UPS) and backup generators to prevent downtime caused by power failures.
2. Regular Maintenance and Monitoring
- Proactive System Monitoring: Use monitoring tools to track the performance of your systems and detect issues before they cause significant downtime. Automated alerts can notify IT teams about potential problems, enabling early intervention.
- Routine Software Updates and Patches: Regularly updating software and applying security patches ensures that systems run smoothly and are protected from bugs, vulnerabilities, or performance issues that may lead to downtime.
- Scheduled Maintenance: Performing routine maintenance during off-peak hours helps prevent unplanned downtime while ensuring systems remain in optimal condition.
3. Disaster Recovery Planning
- Backup and Restore Processes: Regularly back up critical data to secure locations, both locally and in the cloud, to minimize data loss in case of system failure or disaster.
- Disaster Recovery (DR) Plan: Develop and regularly test a comprehensive disaster recovery plan that includes steps for restoring systems quickly and efficiently after an outage. A strong DR plan ensures business continuity even in the worst-case scenario.
- Geographically Distributed Backups: Storing backups across different geographical locations reduces the risk of data loss from regional disasters or localized network failures.
4. Utilize Cloud Services and Virtualization
- Cloud Hosting and SaaS Solutions: Cloud services offer scalability, redundancy, and reliable uptime, especially when compared to traditional on-premise infrastructures. Leveraging cloud hosting for websites, applications, and data storage ensures high availability.
- Virtualization: Virtualizing servers allows for better resource utilization and can reduce the risk of downtime caused by hardware failures. Virtual machines can be quickly migrated to other hosts in case of system failures.
5. Invest in High-Quality Hardware
- Enterprise-Level Hardware: Investing in high-quality, reliable hardware, including servers, storage systems, and network equipment, can prevent failures and ensure higher uptime.
- Regular Hardware Inspections: Perform regular checks and replace outdated or faulty hardware before it leads to potential failures, reducing the risk of unplanned downtime.
6. Employee Training and Knowledge Sharing
- Employee Awareness: Ensure that all employees, especially those in IT and operations, are trained on how to identify and respond to potential system issues. Well-trained employees can troubleshoot and resolve problems more quickly, reducing downtime.
- Knowledge Sharing: Create a knowledge base or documentation for common issues and troubleshooting steps to empower employees to address problems efficiently without needing extensive IT intervention.
7. Automate Processes and Implement AI
- Automation of Routine Tasks: Automating system checks, updates, backups, and other routine tasks reduces human error and increases system reliability, preventing downtime caused by oversights.
- AI for Predictive Maintenance: AI-powered tools can predict system failures before they happen, allowing businesses to perform maintenance or make adjustments proactively, minimizing the chances of unexpected downtime.
8. Establish Strong Vendor Relationships
- Vendor SLAs: Ensure that service level agreements (SLAs) with third-party vendors include strict uptime requirements and penalties for failures. Choose vendors who have a proven track record of reliability and support.
- Backup Vendors: Maintain relationships with backup vendors for critical services such as cloud hosting, payment processors, or hardware suppliers to quickly switch to alternate providers if necessary.
9. Optimize Network Performance
- Load Balancing: Implement load balancing to distribute traffic evenly across servers and prevent overloads that could cause system slowdowns or failures.
- Network Performance Monitoring: Continuously monitor network performance to identify potential bottlenecks, optimize bandwidth, and ensure that connectivity remains stable, reducing the risk of downtime caused by network issues.
10. Regular Testing and Audits
- Stress Testing: Regularly stress-test systems and infrastructure to ensure they can handle peak loads and unexpected traffic surges without failure.
- Uptime Audits: Conduct regular audits to review uptime performance, identify vulnerabilities, and refine strategies for achieving higher uptime.
Maximizing uptime is essential for maintaining business continuity, customer satisfaction, and operational efficiency. By employing these strategies—ranging from redundancy and monitoring to disaster recovery planning and employee training—businesses can significantly reduce downtime and ensure their systems are always available when needed.
Proactively investing in infrastructure, technology, and training creates a resilient environment that can handle challenges and deliver a seamless experience to both customers and employees.
Measuring and Optimizing Uptime
Measuring and optimizing uptime is critical for any business that relies on continuous operations to serve customers, maintain productivity, and ensure the smooth functioning of systems.
Uptime directly impacts performance, revenue, and customer trust, so implementing effective measurement tools and optimization techniques is essential for achieving business goals.
Below are the key steps involved in measuring and optimizing uptime.
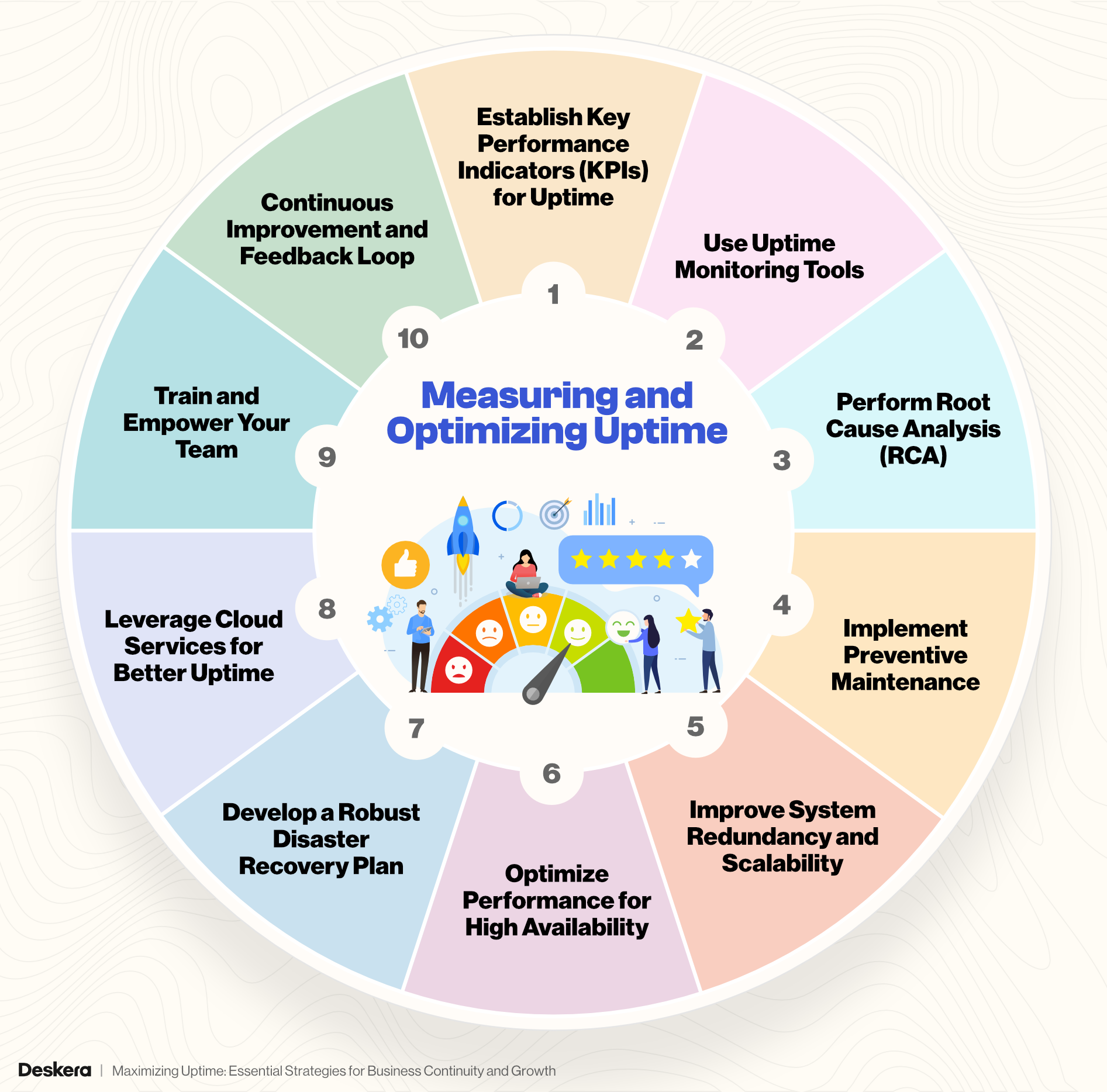
1. Establish Key Performance Indicators (KPIs) for Uptime
- Define Uptime Metrics: The first step in measuring uptime is to establish clear, relevant KPIs that reflect system performance. Common uptime metrics include:
- Total Uptime Percentage: The percentage of time that systems are up and running without interruption. This is the most direct indicator of system reliability.
- Mean Time Between Failures (MTBF): Measures the average time between system failures, helping businesses assess how often interruptions are likely to occur.
- Mean Time to Repair (MTTR): Tracks the average time it takes to restore services after a failure, reflecting the effectiveness of response strategies.
- Set Uptime Targets: Based on industry standards and business needs, set realistic and achievable uptime targets (e.g., 99.9% uptime or better). These targets guide performance assessments and help prioritize actions for optimization.
2. Use Uptime Monitoring Tools
- Automated Monitoring Systems: Implement automated uptime monitoring tools to track and log system availability 24/7. These tools provide real-time alerts in case of downtime, enabling IT teams to respond promptly.
- Tools to Consider: Some popular uptime monitoring tools include Pingdom, Uptime Robot, and New Relic. These tools provide insights into server performance, network connectivity, and response time, making it easier to detect and address issues.
- Reports and Dashboards: Use dashboards and reports to visualize uptime performance. Regularly review these insights to understand trends, pinpoint recurring problems, and make data-driven decisions for improvement.
3. Perform Root Cause Analysis (RCA)
- Identify Causes of Downtime: Whenever downtime occurs, conduct a thorough Root Cause Analysis (RCA) to determine the underlying causes. Whether it's a hardware failure, software bug, network issue, or human error, understanding the root cause helps in implementing corrective actions.
- Trend Analysis: Look for patterns in downtime occurrences. Are certain issues recurring at specific times of the day, during maintenance, or after software updates? Identifying such trends can help in preventing future downtime.
4. Implement Preventive Maintenance
- Scheduled Maintenance: Regularly schedule preventive maintenance checks to ensure systems are running smoothly. This includes updating software, applying patches, and inspecting hardware components for wear and tear.
- Automated Maintenance Processes: Automate repetitive maintenance tasks such as system updates, backups, and performance optimizations to reduce the likelihood of downtime caused by human error or neglected tasks.
5. Improve System Redundancy and Scalability
- Redundant Systems: As mentioned earlier, redundancy plays a key role in maximizing uptime. Implementing redundant power supplies, network connections, and data storage systems ensures that if one part of the system fails, others can take over seamlessly without interrupting service.
- Scalable Infrastructure: Utilize scalable systems, especially cloud-based solutions, that can handle increased loads without degradation in performance. Cloud services, for example, can automatically adjust to spikes in demand, reducing the likelihood of system crashes during high-traffic periods.
6. Optimize Performance for High Availability
- Load Balancing: Distribute system traffic across multiple servers or resources to avoid overloading any single server. Load balancing ensures consistent service availability even during peak periods, preventing performance degradation or outages.
- Content Delivery Networks (CDNs): For websites and web applications, using CDNs can help optimize performance by caching content across multiple global locations, reducing latency and the risk of downtime.
7. Develop a Robust Disaster Recovery Plan
- Backup and Restore Systems: Ensure that your disaster recovery plan includes regular backups of all critical systems and data. In case of a major failure, having secure backups available for fast restoration can minimize downtime.
- DR Testing: Regularly test disaster recovery procedures to ensure that they work efficiently and can restore uptime quickly. Run simulation drills to identify weaknesses and address them in advance.
8. Leverage Cloud Services for Better Uptime
- Cloud-Based Redundancy: Cloud providers typically offer high availability and redundancy, ensuring that your systems remain online even if part of the infrastructure fails. Leverage cloud platforms like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud for their uptime guarantees.
- Disaster Recovery as a Service (DRaaS): Many cloud providers offer disaster recovery solutions as part of their service package, providing businesses with an added layer of protection against downtime.
9. Train and Empower Your Team
- Employee Training: Ensure that your IT team is well-trained and knowledgeable in handling uptime-related issues. Providing them with the tools, processes, and decision-making authority to quickly respond to disruptions can drastically reduce downtime.
- Cross-Functional Collaboration: Encourage collaboration between IT, operations, and customer service teams. When downtime occurs, having a coordinated effort helps in quicker resolution and communication with affected customers.
10. Continuous Improvement and Feedback Loop
- Post-Incident Reviews: After addressing an uptime issue, conduct a post-incident review to evaluate the effectiveness of your response and identify areas for improvement. Use feedback to continuously refine your processes and tools.
- Customer Feedback: In cases where downtime affects customers, actively gather their feedback to understand the impact and improve service delivery.
Measuring and optimizing uptime is an ongoing process that involves monitoring system performance, identifying potential risks, and implementing proactive strategies to minimize disruptions.
By adopting robust monitoring tools, conducting root cause analysis, improving system redundancy, and leveraging cloud technologies, businesses can ensure high uptime and mitigate downtime risks.
A comprehensive approach to uptime measurement and optimization not only enhances operational efficiency but also strengthens customer satisfaction and business continuity.
Future Trends in Uptime Optimization
As businesses continue to rely on digital systems and online services, uptime optimization will become even more critical for ensuring seamless operations, maintaining customer trust, and supporting business growth.
With advancements in technology, new trends are emerging that promise to further enhance uptime and reduce the likelihood of disruptions.
Below are some of the key future trends in uptime optimization:

1. AI and Machine Learning for Predictive Maintenance
- AI-Driven Monitoring Systems: The future of uptime optimization will be closely tied to AI-powered tools that can predict failures before they occur. By analyzing large volumes of historical data, machine learning algorithms can detect patterns and anomalies that indicate impending system failures.
- Proactive Maintenance: AI systems will not only predict issues but also suggest preventive actions, such as hardware replacements, software updates, or load adjustments, ensuring that systems remain operational without unplanned downtime.
- Self-Healing Systems: AI-driven technologies are moving toward creating self-healing systems that can automatically resolve issues, adjust configurations, and re-route traffic without human intervention, leading to higher uptime.
2. 5G and Edge Computing for Faster Response Times
- 5G Network Reliability: With the widespread rollout of 5G technology, businesses can expect significantly faster and more reliable network connections, which will be crucial for improving uptime in real-time applications, such as IoT devices and cloud-based services.
- Edge Computing: By processing data closer to the source (at the "edge"), edge computing reduces latency and ensures higher reliability, especially for time-sensitive applications. This trend is particularly important for industries like manufacturing, healthcare, and autonomous vehicles, where uptime is critical for safety and performance.
3. Cloud-Native Infrastructure and Multi-Cloud Strategies
- Cloud-Native Architectures: More companies will adopt cloud-native designs, using microservices and containerization to ensure that their systems are flexible, scalable, and resilient. Cloud-native infrastructure is inherently more reliable and can quickly recover from disruptions, offering higher uptime than traditional monolithic systems.
- Multi-Cloud and Hybrid Cloud Strategies: Businesses will increasingly rely on multi-cloud environments, where services are spread across different cloud providers. This reduces the risk of downtime due to outages at a single cloud provider, ensuring better redundancy and uptime guarantees.
4. Automation and Orchestration Tools
- Automated Scaling: Future uptime optimization will involve more automation, especially in scaling infrastructure to meet changing demand. Automated systems can dynamically allocate resources, ensuring that services remain available even during traffic spikes or system failures.
- Orchestrated Disaster Recovery: Disaster recovery processes will become more automated and orchestrated, with recovery workflows pre-defined and managed by intelligent systems. This will enable faster and more efficient responses to outages, significantly reducing downtime.
5. Blockchain for Enhanced Security and Uptime
- Blockchain for Redundancy: Blockchain technology can provide a decentralized, immutable ledger that ensures the reliability and availability of critical systems and data. By using distributed ledgers across multiple nodes, businesses can reduce downtime due to server failures or security breaches.
- Enhanced Security: Blockchain's secure and transparent nature also helps protect against cyberattacks, which are one of the leading causes of downtime. As security becomes more integrated into uptime strategies, blockchain will play a key role in preventing downtime caused by security incidents.
6. Zero-Downtime Deployment and Continuous Integration/Continuous Deployment (CI/CD)
- Zero-Downtime Deployment: One of the future trends in uptime optimization will be the widespread adoption of zero-downtime deployment techniques. Businesses will use advanced deployment strategies, such as blue-green and canary deployments, to ensure that new features and updates can be rolled out without affecting system availability.
- CI/CD Pipelines: Continuous integration and continuous deployment (CI/CD) will become more streamlined, enabling faster updates and releases while ensuring system reliability. Automated testing and deployment will allow for the quick identification of potential issues and reduce the risk of downtime during updates.
7. Smart Infrastructure Management with IoT
- IoT-Enabled Infrastructure Monitoring: The integration of IoT sensors into infrastructure will allow businesses to monitor the health and performance of hardware in real-time. By collecting and analyzing data from these sensors, companies can identify potential failures and take proactive steps to prevent downtime.
- Predictive Analytics for Hardware Maintenance: IoT devices will also be able to use predictive analytics to forecast when specific components of infrastructure, such as hard drives or network devices, are likely to fail. This enables businesses to replace or repair equipment before it causes any significant downtime.
8. Autonomous Network Management
- Self-Optimizing Networks: Future networks will be increasingly autonomous, capable of self-optimizing and self-healing without human intervention. Using AI, networks can detect congestion, adjust routing paths, and resolve bottlenecks, minimizing the risk of downtime caused by network failures.
- Automated Network Failover: In the future, network failover mechanisms will be automated, ensuring that if one path fails, traffic is quickly rerouted to another network, keeping systems up and running without interruption.
9. Enhanced Service Level Agreements (SLAs) and Uptime Guarantees
- Stricter Uptime Guarantees: As businesses demand higher reliability, cloud providers and third-party service vendors will offer stricter SLAs with more aggressive uptime guarantees (e.g., 99.99% or even 99.999% uptime).
- Performance-Based SLAs: SLAs will evolve to include performance metrics beyond simple uptime, such as response time, transaction speed, and system load capacity, ensuring that services meet the expected standards for both availability and performance.
10. Sustainability and Green IT for Uptime
- Sustainable Data Centers: As businesses become more environmentally conscious, there will be a push toward sustainable IT infrastructure. Green data centers using renewable energy sources and energy-efficient technologies will help reduce the risk of downtime caused by power outages or inefficient operations.
- Low-Carbon Uptime Optimization: Companies will seek to optimize uptime in a way that also benefits the environment, balancing energy use with uptime goals. Low-carbon operations will help ensure long-term system reliability while contributing to sustainability efforts.
The future of uptime optimization is poised to be shaped by cutting-edge technologies such as AI, 5G, blockchain, and automation, enabling businesses to not only maximize system availability but also proactively address potential risks.
As digital transformations accelerate across industries, uptime optimization will become more sophisticated, relying on smarter, self-healing systems, highly redundant infrastructures, and real-time monitoring to prevent downtime.
By embracing these emerging trends, businesses can ensure that they remain competitive, reliable, and capable of delivering seamless experiences to their customers and users.
How Deskera ERP Can Help You Maximize Uptime
Deskera ERP offers a range of features that can significantly enhance uptime for businesses by streamlining operations, improving system reliability, and providing real-time insights. Here’s how Deskera ERP can help you maximize uptime:
1. Real-Time Monitoring and Analytics
Deskera ERP provides real-time dashboards that give a comprehensive view of your business operations. By closely monitoring key metrics and performance indicators, businesses can quickly identify potential issues, allowing them to take proactive measures before they result in downtime. This helps in minimizing interruptions and ensuring smooth operations.
2. Automated Processes and Workflows
With Deskera ERP, many routine tasks such as inventory management, order processing, and financial reporting are automated. Automation reduces the likelihood of human errors that can lead to system failures or disruptions, thus enhancing overall uptime. Businesses can also schedule tasks during non-peak hours to ensure there is no impact on system performance.
3. Cloud-Based Architecture for High Availability
Deskera ERP is hosted on the cloud, ensuring that your business systems are always accessible. The cloud infrastructure is designed for high availability, meaning your ERP system is less likely to experience downtime due to server issues. In the event of a localized issue, cloud redundancy ensures minimal disruption.
4. Scalable Infrastructure for Growing Businesses
As your business grows, Deskera ERP can scale to meet your evolving needs without compromising uptime. The system automatically adjusts to increased demand, ensuring that resources are allocated efficiently and your systems stay operational even during periods of high traffic or peak demand.
5. Automatic Data Backup
Deskera ERP includes automatic data backup, ensuring that your data is always protected. If a system failure does occur, businesses can recover quickly without experiencing extended downtime. This framework ensures continuity and reliability in the face of unexpected disruptions.
6. Seamless Updates and Maintenance
With Deskera ERP, system updates and maintenance can be performed seamlessly in the background without interrupting business operations. Automated updates ensure that your system is always up to date with the latest features and security patches, minimizing vulnerabilities and potential downtime caused by outdated software.
By leveraging these features, Deskera ERP can help businesses optimize uptime, ensuring consistent operations and reliable service delivery for customers.
Key Takeaways
- Uptime is crucial for maintaining operational efficiency, customer satisfaction, and business continuity. Prioritizing uptime ensures that your systems are consistently available, avoiding costly disruptions that can impact productivity and revenue.
- Adhering to industry uptime standards, such as 99.9% or 99.99%, helps businesses maintain reliable services. Understanding the downtime allowed by different uptime percentages can guide businesses in setting realistic expectations for system reliability and investing in the right infrastructure.
- Downtime can have far-reaching consequences, from lost productivity to damaged customer trust. Minimizing downtime through proactive measures is essential for maintaining a competitive edge and safeguarding long-term business relationships.
- Identifying and addressing common causes of downtime, such as hardware failures, software issues, or cyberattacks, is key to reducing disruptions. Preventive measures, including regular maintenance and system monitoring, are vital for ensuring operational continuity.
- Implementing strategies like proactive maintenance, robust disaster recovery plans, and system redundancy can significantly increase uptime. Leveraging technology such as AI and automation also plays a crucial role in optimizing uptime and minimizing risks of disruptions.
- Consistently measuring uptime through monitoring tools and analyzing downtime trends helps identify areas for improvement. Optimization efforts should focus on minimizing response times, automating recovery processes, and ensuring high system availability.
- Emerging technologies such as AI, 5G, edge computing, and blockchain will revolutionize uptime optimization. Adopting these technologies enables businesses to predict failures, automate fixes, and improve system reliability, ensuring higher uptime in the future.
- Deskera ERP enhances uptime through real-time monitoring, automation, and cloud-based infrastructure. By offering scalable, reliable solutions with automatic backups, Deskera helps businesses maintain continuous operations and minimize downtime risks.
Related Articles
 Niti Samani
Niti Samani RVJ
RVJ Niti Samani
Niti Samani Niti Samani
Niti Samani Niti Samani
Niti Samani Niti Samani
Niti Samani


